
A paper by Paul Koerbin, Supervisor, Digital Archiving Section, National Library of Australia presented at the 4th International Web Archiving Workshop on 16 September 2004 in Bath UK.
Abstract:
This paper describes the workflows and processes undertaken by the National Library of Australia (NLA) in archiving web resources for PANDORA: Australia's Web Archive. It considers the workflows and processes with regard to how they are supported by the functionality of the web archiving management system developed by the NLA, the PANDORA Digital Archiving System (PANDAS). It includes a summary of the Australian approach to web archiving and an overview of the PANDAS system architecture.
The function of the National Library of Australia as stated in the National Library Act 1960[1] is to maintain and develop a national collection of library material, including a comprehensive collection of library material relating to Australia and the Australian people; and, moreover, to make this material available. With the advent of the Internet as a major medium for the publication of such material, the Library, as the primary institution in Australia charged with the responsibility for preserving Australia's documentary heritage, established the PANDORA Archive as a means to collect and manage online resources.
Currently in Australia, in the federal jurisdiction, there is no legal deposit provision covering electronic publications, so the National Library must seek the explicit permission of publishers to harvest the online resources and to make the archived copies publicly accessible from the PANDORA Archive.
The National Library of Australia established the PANDORA Archive in 1996. The first tasks involved determining what would be included in the Archive and the drafting of selection guidelines while harvesting began in early 1997[2] .
The National Library of Australia adopted a selective approach to archiving Australian web resources. All agencies that are responsible for archiving web resources are faced with the decision as to what archiving approach to take: whether to attempt whole or substantial domain archiving, or to be selective. The decision the National Library made was largely pragmatic and not for reasons that discredit the larger domain archiving options – indeed a combination of approaches is most likely to achieve the best overall results. The selective approach has allowed the Library to make the best use of very limited resources. It has also fostered a ‘get in and do it’ attitude which in turn provides practical insight into web archiving issues and incentive to deal with the specific problems encountered. This is not to ignore the problems and shortcomings associated with selective archiving, which I will briefly mention in the concluding remarks of this paper.
The development of PANDORA[3] as a web archiving system commenced as a 'proof-of-concept' project; that is, as a practical rather than theoretical undertaking. This meant that practical procedures involved in archive building were adopted as they became possible at the same time as the technical infrastructure was developed. So, for example, the selection of sites for archiving was begun before archiving could commence. Initially harvesting was done using the Harvest[4] software developed by the University of Colorado. Harvest was an indexing software and was modified by the National Library for archiving purposes. A rudimentary user interface, known as Pantrack, was developed as a sub-system to Harvest to allow PANDORA staff to submit and schedule archiving request and log archiving problems. In order to manage administrative metadata, an Access database was subsequently created which operated independently of the archiving system and Pantrack. The lack of integration of the system was further compounded by the adoption of desktop harvesting robots (initially the offline browsing software WebZIP[5] then HTTrack[6] ). The adoption of desktop archiving was made necessary by the increasing prevalence of JavaScript which the Harvest HTML parsing program could not handle. While recognising that this approach is piecemeal, it also achieved results in that there are archived instances dating back to early 1997 in the PANDORA Archive. What was understood from this process was the need for an integrated web-based management system. This need was made all the more urgent by the move to a distributed model for the responsibility for web archiving in Australia which saw the engagement of other interested organisations as PANDORA partners.[7]
The National Library of Australia has a role in leading and providing direction to the Australian library community. While it was natural that the Library initiate and lead the development of web archiving it was also important to engage other institutions in the process in order to make use of local identification and selection knowledge and share the workload and responsibility. The State Library of Victoria was the first to formally become a PANDORA partner followed by ScreenSound Australia, Australia's National Film and Sound Archive. As of today, all mainland state libraries, that is, in addition to the State Library of Victoria, the State Libraries of New South Wales, Queensland, South Australia and Western Australia, together with the Northern Territory Library and Information Service are PANDORA partners. In addition, the Australian War Memorial and the Australian Institute of Aboriginal and Torres Strait Islander Studies have now joined as PANDORA partners. The State Library of Tasmania, it should be noted, has for many years developed its own web archiving system known as Our Digital Island[8] . The National Library is still responsible for more than 57% of the archived titles and more than 66% of the archived instances in PANDORA[9] .
As of August 2004 an indicative size of the PANDORA Archive can be represented by the following figures. These figures only refer to the Archive's access display copy, an uncompressed copy of the Archive content maintained on the PANDORA web server for public access through the PANDORA home page. As noted below, the Archive actually contains two preservation copies of each archived instance together with associated metadata including a metadata master or 'shadow' copy for each archive instance[10] .
| Number of titles: |
6,608 |
| Number of instances: |
13,165 |
| Number of files: |
21,117,595 |
| Size in gigabytes: |
702.1 |
In regard to what is archived - that is the content of the Archive - this is dependent upon the selection decisions and objectives of the contributing partners. However, the content selected is not constrained by technical format, nor by any narrow definition of what an online publication may be[11] . Therefore, the content of the PANDORA Archive - the entities referred to as 'titles' in the above statistics - ranges from simple print like publications produced as single PDF files to complete complex web sites incorporating multimedia content (and everything in between). So too, a part of web site - for example the pages of a government web site containing the speeches of the minister or officials - may be selected as a PANDORA title just as readily as a single document-like title or a whole web site domain. As such, the content is not easily or simply characterised. The content reflects the combined selection objectives and activities of the PANDORA partner agencies - activities and objectives which do indeed differ between the contributing partners and may differ over time within any one agency depending on such factors as available resources and identified priorities.
The PANDORA Digital Archiving System, known as PANDAS, was developed in-house following an unsuccessful attempt to find an off-the-shelf system (or systems) to provide an integrated, web-based web archiving management system. The need for such a system was evident as the scale of the Library's archiving activity increased and if the best possible efficiencies were to be achieved in building a collaborative, selective and quality assessed web archive.
PANDAS was first implemented in June 2001 and a second much enhanced version was released in August 2002. The second version was more modular in design to facilitate future enhancement by allowing development to component parts of the system. Consequently the current development program includes a number of incremental upgrades - as at the end of June 2004 version 2.1.5 is in production and version 2.2 is under development - as well as concurrent development of what for working purposes is characterised as PANDAS version 3 and which will include more systemic enhancement.
The system architecture consists of four layers: presentation, application, business and data (Figure 1.).
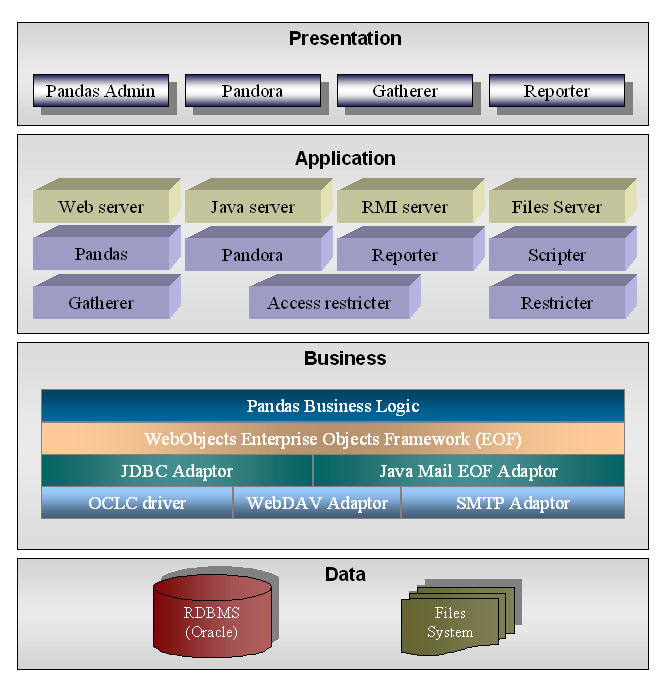
Figure 1. PANDAS Architecture
While it is not within the scope of this paper to describe the system architecture in detail, some characteristics of the system should be mentioned. What is referred to generally as PANDAS is in fact a combination of several individual server applications sharing a set of functionalities through application modules (see Figure 2. for the complete system model). These component modules include:
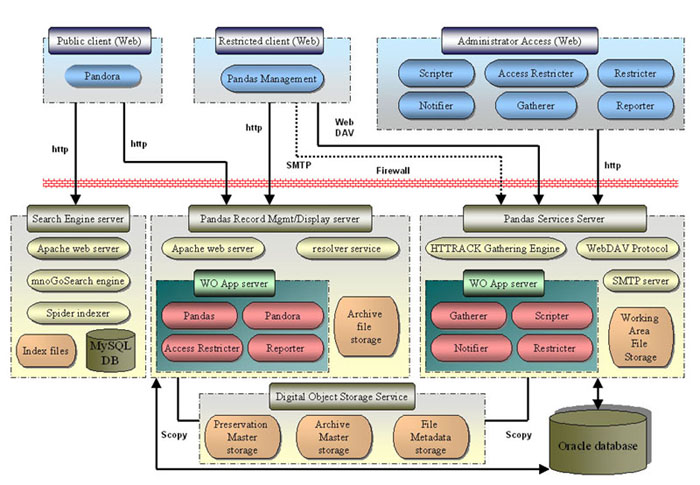
Figure 2. PANDAS Data Model
PANDAS was designed to support the workflows defined by the staff of the Library's Digital Archiving Section[15] . These workflows include:
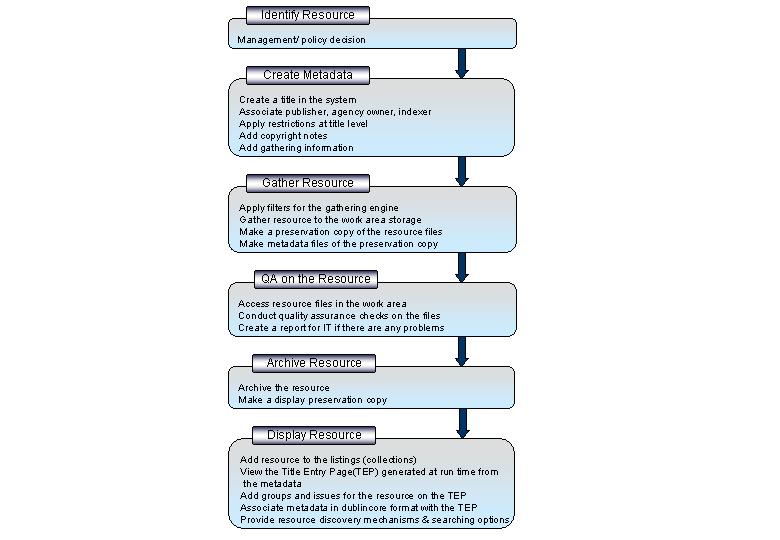
Figure 3. PANDORA Workflows
In broad terms PANDAS supports these workflows by means of the following functions:
I will consider each of these functions in more detail in relation to PANDORA web archiving workflows.
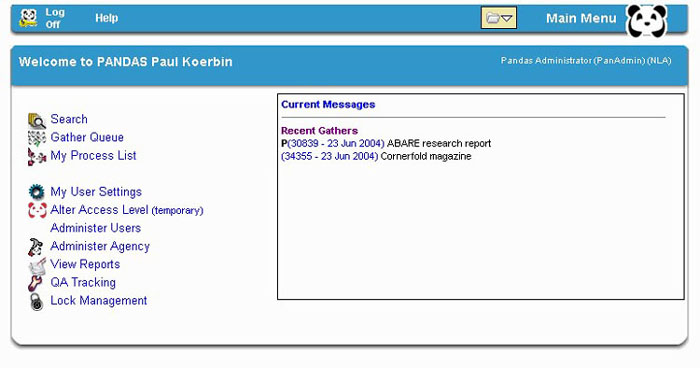
Figure 4. PANDAS Main Menu Screen
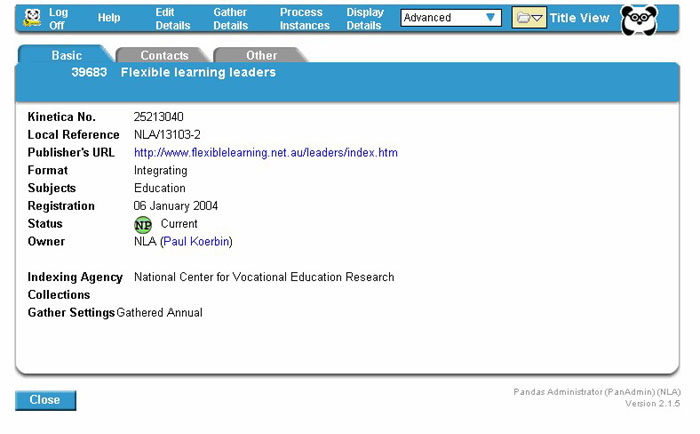
Figure 5. PANDAS Title View Screen
User level and agency responsibilities for registered titles
The PANDAS user interface supports four user levels. Higher user levels inherit all the permissions of the preceding levels. They are:
The task of identifying and selecting candidate titles for inclusion in PANDORA is currently undertaken outside the management system. All PANDORA partners have collection responsibilities, whether that is based on a specific jurisdiction (as for the respective state and territory libraries) or topical interest (as in the case of ScreenSound Australia, the Australian War Memorial and the Australian Institute of Aboriginal and Torres Strait Islander Studies). Responsibilities may not necessarily be clearly delineated however and users search PANDAS as part of the selection process to determine if a selection decision in regard to a specific publication has already been made by another PANDORA partner. PANDAS identifies the agency responsible for a registered title and its current status (e.g. 'national preservation', 'rejected', 'monitored' or 'pending selection').
Titles registered on PANDAS by one agency can be viewed but not be edited by staff in another agency. However PANDAS includes functionality to transfer ownership of a title record between participating agencies. This allows, for example, for one agency to identify and register a title onto the system and then transfer that title to another agency (for whom responsibility may be more appropriate), for that agency to make the selection decision. This process initiates an email notification that alerts the agency that a title has been transferred. The title also appears in a message box on the PANDAS main menu screen of the relevant Agency Administrator. Should an agency locate a title on PANDAS registered as 'rejected' and wish to change that decision to being selected for 'national preservation' the title can be transferred and the status changed and responsibility assumed by that agency.
Categories of metadata recorded
The administrative metadata recorded can, for the purpose of this paper, be considered under four broad categories. The metadata is not grouped under such categories on the PANDAS screens.
The metadata is recorded in four distinct record types that can be registered on PANDAS:
I will expand on some of the metadata elements that may be less self-explanatory.
Metadata identifying original resources
In addition to the registering agency owning the record by default, an individual user registered with the agency can take ownership of the title. This action means that the individual will receive notification of completed harvesting events and their gathered instances will be listed in their personal 'Processing List. The Agency Administrator is able to assign ownership to agency staff and thus manage the distribution or work.
Trusted indexing and abstracting agencies are registered in the system. When they notify the Digital Archiving Section (via a web form) of a candidate title for archiving, the identifying indexing agency is associated with the title. When the title has been archived the relevant indexing agency will receive an automated email message - sent to one or more email addresses included in the PANDAS record for the indexing agency - to notify them that the title is now archived and providing them with the persistent identifier URL.
Selection and archiving status metadata
A selection status such as 'national preservation' or 'rejected' or 'monitored' will have a number of associated standings that further define the status. In the case of titles selected for 'national preservation' the standings define the archiving status; for example, the standing 'current' indicates that the title is being archived on an ongoing scheduled basis, while the standing 'complete' indicates that the archiving process in not scheduled or ongoing. Other standings indicate such things as: that the title has disappeared from the web; permission to archive was not able to be obtained; or, that the site is unable to be archived (although still considered selected for national preservation). A number of these standings determine the wording that appears on the automatically generated title entry pages. So, a 'national preservation' title with a standing of 'current' will produce the text 'this title is archived regularly' on the title entry page.
Access management metadata
Access management metadata includes the allocation of a persistent identification number. This is a system generated running number allocated to the title record which is subsequently incorporated into archived resource's persistent URL (which will be discussed further below).
There is also an option to include the title in a predetermined collection. Collection records are registered on PANDAS independently of titles. Once a collection record is established, title records can be associated with a collection and as a result will be listed on a collective title entry page. This functionality is commonly used to organise collections of web sites associated with events such as election campaigns where the sites may be a compilation of ephemeral (and substantial) web sites, but which the collection manager determines are more likely to be of interest as a collection. The concept of collection in PANDORA should be understood as distinct from the established subject listings. A title included in a collection and listed on a collection title entry page can also be listed as an individual title under a subject listing thus opening up multiple discovery routes.
As mentioned at the beginning of this paper, electronic publications are not covered by legal deposit at the federal level in Australia. Therefore, archiving permission must be sought and the permission status (i.e. granted, denied, unknown) is recorded in the management system. The actual correspondence with publishers - usually conducted exclusively by email - is maintained in an external system (at the National Library this is the electronic registry file system TRIM[16] ) and the registry file number is recorded as a 'local reference' number.
As part of the process of obtaining permission to archive it may be necessary to negotiate access restrictions (typically in the case of commercial publications). Access restrictions are set at the title level. Three types of access restriction can be applied: period restriction, date restriction and authenticated restriction.
Period and date restrictions are applied in conjunction with locations (a range of IP addresses and subnet masks) to which the access is limited. For example, access may be restricted to staff-only areas of the National Library or to a single PC in the Library's Main Reading Room. These restriction locations must be programmed into the system and are not maintained through the user interface.
Multiple access restrictions can be applied to an individual title. So, for example, access may be restricted for three years in the National Library of Australia Reading Room and for two years in the State Library of Victoria Reading Room.
PANDAS utilises HTTrack to harvest files from the web, however PANDAS provides the additional functionality of scheduling the harvesting process. An appropriate harvesting regime for the title is determined by the collection manager responsible for the title, although this may be in consultation with the publisher of the resource. In determining a schedule, consideration is given to the type of publication - an integrating resource or e-journal will in most cases be archived on a regular basis, whereas a monographic type publication would only be archived once - as well as to the stability of the publication and how long information is retained on the site. Generally, a longer harvesting schedule is preferred and, while no attempt is made to capture all changes to a site as they occur, it is the aim to ensure that all substantial content is captured.
Three types of scheduling are supported by PANDAS:
These scheduling methods can be used in combination.
The PANDAS user interface includes functionality to specify gather filters, a range of settings and login/password requirements. These options largely emulate the options found on the WinHTTrack interface[17] . However the PANDAS interface is intended to be essentially generic so that other harvesting software can be connected to PANDAS in a manner that is transparent to the user[18] . A number of default settings are established which can be over-ridden by the user. These include:
The limit on archiving depth is large enough to encompass any web site but is applied in order to thwart regressive interrogation of the server hosting the web site being harvested. Other limitations on the harvester are applied so as to reduce the likelihood of aggressive harvesting including a limit of six connections per server accessed and a transfer rate of 50 Kb per second. A download limit of one gigabyte is also applied although this is more to facilitate functionality within the bandwidth available to the National Library.
As a web archiving system PANDAS is primarily designed to manage the harvesting (downloading) of files from the web. However the system also supports an uploading functionality. While the ability to upload files is an essential component of the quality assurance process associated with harvested resources (see below) it can also be used to ingest new resources (whether single files, multiple files or whole web sites) from a local drive. This procedure may typically be used when a site cannot be successfully harvested from the web and the publisher has supplied the files by other means (e.g. FTP or on CD). It is also commonly used for uploading publications supplied as email attachments. The ability to upload from local drives to the working area server is achieved using the WebDAV protocol[19] . In order to do this an empty archive instance (i.e. an archive directory path) must first be created to which the uploaded files can be added. This simply involves selecting this method from the options available in the gather module interface. As with harvesting, this upload process can be initiated either at the time of upload or can be scheduled. Uploading to the archive can only be done by authorised PANDAS users, not by external parties.
The PANDAS interface allows the user to view the gather queues which identify titles in the process of harvesting, those waiting to be harvested and those that have finished harvesting and are awaiting quality assurance processing. The title owner or Agency Administrator can pause, stop or delete the harvest when displayed in the gather queues. To further control the use of bandwidth, currently PANDAS allows only four titles to be downloaded concurrently. If there are more titles set to be harvested than there are available connections, they will queue in a waiting list until a connection becomes available. Scheduled harvests are commenced after midnight on the day they are scheduled to run, so most (if not all) the harvesting is usually completed before staff commence work. However common practice is to also to initiate immediate harvest requests during working hours to suit agency or individual workflows.
The owner of a harvested title is notified of titles awaiting processing by means of a message on their personal view of the main menu. The user can link from this message directly to the processing screen for the title. Other routes to the processing of title are also available, either from the completed gather queue, the title record or the user's personalised processing list which includes newly harvested instances as well as those already accessed but yet to be archived.
Harvested files are initially located on a file server designated as the 'PANDAS working area'. That is, they are not considered 'archived' at this stage. While the files are in this working area, the PANDAS user can delete the instance and can open write access to the files using the WebDAV protocol.
The checking of an instance for functionality and the completeness - or more correctly, the accuracy - of the harvest is a manual process. This remains the most time-consuming aspect of the archiving process. However, such a process is considered a necessary aspect - indeed one of the advantages - of the selective archiving approach. Essentially this involves the user doing a visual check of the site, following links and noting the completeness and functionality of the site; and determining that the look and feel of the original has been retained. Since this is a visual checking process, some subtlety and experience is required, since there are a number of traps for the unwary. By way of example I will mention three such considerations:
In some cases, where the archived version is incomplete or not fully functional, PANDAS users (that is, the collection managers) are able to put into effect solutions, such as downloading missing files and perhaps some minor re-referencing in the HTML. It depends on the skill of the user how much can be done, but PANDAS collection managers are expected to undertake basic repair work.
More complex problems, such as those involving JavaScript or decompiling class files to identify missing resources, are referred to technical support drawn from staff in the National Library's Information Technology Division. PANDAS includes a reporting functionality within the processing screen to identify and describe problems and 'hand-over' the title and associated error report to the technical support for analysis and resolution where possible. PANDAS includes a tracking system for these reports. When the problem has been dealt with by the IT technical support person it is handed back through the system to the title owner who will be notified through the previously mentioned message system on their personal view of the main menu.
The decision whether or not to archive the instance remains with the collection manager who is the business owner of the title. In some cases it may be a matter of deleting the instance and re-setting gather filters to include or exclude certain files or directories. In cases where full functionality or all files cannot be obtained, the collection manager must determine if the instance should still be preserved in its incomplete state.
When a collection manager decides to accept an instance they select the 'archive' option on the processing screen. This initiates a script that packages the quality assessed instance as a gzip compressed tarball (TAR, tape archive format) file and moves it to the Library's Digital Object Storage System (DOSS)[21] . Thus any changes made to this copy are retained as the display master copy. In addition to the display master, another unaltered copy is stored on the DOSS. This copy, known as the preservation master, is derived from the output of the harvesting software and does not include any human or machine interventions (other than that resulting from the harvester). A third master copy is stored as a metadata master which may be understood as a 'shadow' copy of the harvested instance in which the contents of each original file has been replaced with the HTTP response header for that file from the original site's web server. This master may perhaps more correctly be termed a MIME (Multipurpose Internet Mail Extension) master since the significant content for preservation purpose of this shadow copy is the MIME type[22] . Finally, when the archiving of an instance is initiated, the archive script also creates an access copy. This is an uncompressed copy of the display master which is moved to the PANDORA web server. This is the copy that is publicly accessible through the PANDORA home page.
The archived copies can therefore be summarised as follows:
The public interface component of the PANDORA Archive consists of a combination of pages generated on the fly from the PANDAS database together with a number of static HTML pages. The latter include various manuals and informational pages.
The pages generated from the database provide the browsable access to the PANDORA resources by means of alphabetical title listings and portal-like subject listings. Each archived resource, corresponding to a registered title on PANDAS, has a title entry page (TEP). The TEP (see Figure 5) includes the following information, some of which is derived from the administrative metadata recorded on the title record, while other components are edited though the Display Details screens:
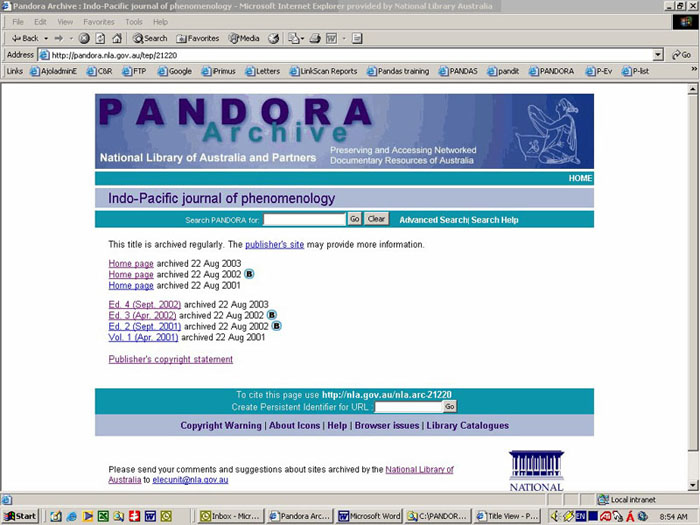
Figure 6. PANDORA Title Entry Page
As already noted, PANDAS assigns a persistent identifier (a system generated running number) when a title is registered. This number is incorporated into the persistent URL applicable to the title's TEP. The PANDAS persistent identifier is incorporated into a schema developed by the National Library of Australia for its various digital collections[23] . This schema incorporates a collection identification element for the archive (nla.arc), and the PANDAS persistent identification number. An example, as for the title in Figure 5 is http://nla.gov.au/nla.arc-21220. This scheme can be logically extended to deep resources within the archive by adding elements to the base identifier to identify the archived instance and the resource file. Thus http://nla.gov.au/nla.arc-21220-20030822-www.ipjp.org/september2002/schweitzer-ed.html is the persistent identifier for the archived editorial page of the September issue of the Indo-Pacific Journal of Phenomenology as archived on 22 August 2003. In order to facilitate the identification of these deep persistent identifiers, a citation generator is accessible from the PANDORA TEPs and the PANDORA citation generator page[24] . This allows a reader to copy and paste the Archive URL of a deep resource into the generator box which will calculate the persistent URL.
All titles archived in PANDORA are catalogued with full MARC records onto Kinetica, the Australian National Bibliographic Database (NBD), and the National Library's own online catalogue. When the MARC record has been added to the NBD it is possible to initiate from PANDAS a Z39.50 query to extract MARC data which is then cross-walked to Dublin Core metadata elements[25] which are then embedded in the TEP. Currently this query has to be initiated by the PANDAS user.
One other access element to mention in regard to access and discovery is the ability to limit the PANDORA home page listings (title and subject) to specified partner views. Thus, for example, it is possible to view only those titles archived by the National Library of Australia or only those archived by the State Library of New South Wales. While this functionality is present it is somewhat underdeveloped at present especially in regard to clear branding.
PANDAS includes a reports module in which a number of pre-defined reports are viewable through the user interface at any time by users with administrator privileges. These reports can also be programmed to run at defined times, in which case a notification is sent to the relevant agency's email address.
These pre-defined reports include:
These reports can be viewed in relation to all agencies or for a specified agency.
Ad hoc reports cannot be run through the PANDAS interface; however SQL queries can be run over the Oracle database by a collection manager with appropriate access rights and software (e.g. Oracle Report Builder). For user defined statistical reporting the National Library has been testing the ProClarity Analytics Platform[26] which provides data cube manipulation and analysis capabilities.
In order to report on broken publisher URLs which are displayed on the title entry pages, the link checking software LinkScan[27] is used. These reports identify broken links (404 errors) and other URL problems such as invalid URL schemes. Acting on these reports can involve considerable work in order to determine if the site has disappeared from the Internet or if it has a new location. In addition, these changes will require information in PANDAS to be updated and in many cases editing of the MARC catalogue record.
Future developments and directions for PANDAS and web archiving in Australia address both current system issues - debugging, enhancements to existing modules - and more systemic issues.
The process of enhancing PANDAS is understood as an ongoing one. Planning for PANDAS version 2, for example, was well underway as PANDAS version 1 was being implemented. Since PANDAS version 2.0 was released in August 2002 there has been a considerable amount of debugging work and minor enhancements deployed in incremental upgrades. Desired enhancements to existing modules have been identified and are currently being progressively implemented. The sorts of enhancements encompassed in this work include changes to existing functionality to better support workflows and improve system performance.
With increased PANDORA partner participation, heavier archiving loads and the regular archiving of large web sites, some problems in respect of the robustness and stability of the system have become evident. These problems relate in some part to the available hardware capabilities, such as memory and processing capacity, but also stem from the way the development environment, WebObjects, has been used. At the time that PANDAS was developed some five years ago, training and support for WebObjects was not readily available in Australia and one consequence of this was some sub-optimal use of the development environment which has been identified as the cause of some problems of stability in the production environment. The National Library is now proposing to re-engineer the PANDAS software to address this issue and migrate PANDAS to the later and better supported WebObjects 5.2. As this version of WebObjects is compliant with Java Enterprise Standards this will allow for the software to be deployed on standard Java Application Servers, a factor that will better enable possible collaborative development.
A number of factors driving future developments will have significant implications for the system and workflows. These include:
In respect of the ingest of larger volumes of online publications, the Library has begun working towards automating the process of identifying resources using MARC records derived from metadata emanating from Australian Commonwealth Government agencies and using this to automatically register and harvest resource through PANDAS.
The National Library as a member of the International Internet Preservation Consortium[28] is currently leading the Consortium's Deep Web Working Group researching and developing strategies and tool for archiving web content that is inaccessible to crawlers.
In adopting a selective approach to archiving and developing an archive system initially as a proof-of-concept model, the National Library of Australia has been able to achieve tangible web archiving outcomes while continuing to develop, extend and refine its systems and workflows. The scalability of the selective approach, which allows for the negotiation of permission to archive with rights owners and quality assurance in the archiving process, supports the building of an accessible, functional and undoubtedly valuable web archive.
In taking up practical web archiving at an early stage while concurrently developing the system it is true to say that the management system that was created was designed to specifically meet the workflows that were being established by the National Library of Australia.
The shortcomings of selective archiving must however be recognised. While the Australian domain is perhaps of a size to make selective archiving a valuable pursuit, nevertheless much - the greater part - of the Australian domain remains un-archived by PANDORA. This puts great onus on the selection process, but it will always be a fraught undertaking to try and pre-empt all that future researchers may require or desire. Moreover as Catherine Lupovici has emphasised,[29] the web - or any specified domain within it - is an entity is in which the linkages form part of the essential character that ought to be preserved. This cannot be achieved with selective archiving of the type demonstrated by PANDORA.
It must also be recognised that selective archiving as done in Australia does retain a degree of manual intervention, specifically in the selection, quality assurance and cataloguing processes, that requires considerable resources in order to achieve archiving on any useful scale.
The ambition for web archiving in Australia is to develop a system able to automate as many of the web archiving processes as possible while retaining a commitment to quality archiving outcomes. In doing this we aim to be able to increase the scale of archiving and be able to incorporate a range of archiving approaches including quality assessed selective archiving and large scale domain or partial domain harvesting. The Australian experience at least demonstrates that, even with minimal and inevitably inadequate resources, a practical approach can achieve valuable results in the form of a working, accessible web archive while at the same time serving to promote system development and useful engagement in the ongoing work to address the problems of this essential pursuit.
I wish to acknowledge and thank Vinita Tuteja of the IT Applications Branch at the National Library of Australia for her documentation of the PANDAS system architecture from which much of the description in this paper is derived; and for her diagrams of the PANDAS architecture, system model and workflow. I also wish to thank Steven McPhillips of the Business Systems Support Branch at the Library for clarification of a number of technical aspects in regard to the system.
[1] http://www.austlii.edu.au/au/legis/cth/consol_act/nla1960177/s6.html
[2] The earliest archivings appear in the Archive with instance dates indicating July 1997, the date of their importation into the archiving system. In fact, some were harvested in the preceding months.
[3] The name PANDORA is commonly used as the name for the National Library of Australia's web archiving initiative, as in PANDORA : Australia's Web Archive, see: http://pandora.nla.gov.au. However, in respect of the system architecture that is discussed in this paper, PANDORA also refers to the specific system component that provides the public interface to the archived resources.
[4] For some information about Harvest, see: http://archive.ncsa.uiuc.edu/SDG/IT94/Proceedings/Searching/schwartz.harvest/schwartz.harvest.html
[5] http://www.spidersoft.com/webzip/default.asp
[7] For more background on the early development of PANDORA and PANDAS see, Cathro, Warwick. Archiving the Web: the PANDORA Archive at the National Library of Australia. (2001) http://www.nla.gov.au/nla/staffpaper/2001/cathro3.html. For a brief and more recent overview of PANDORA web archiving activity see Phillips, Margaret. PANDORA, Australia's Web Archive, and the Digital Archiving System that Supports It. (2003). http://www.nla.gov.au/nla/staffpaper/2003/mphillips1.html
[8] http://odi.statelibrary.tas.gov.au/
[9] Based on figures as at June 2004.
[10] For an explanation of the various preservation master and access copies maintained in the Archive, see below in the section headed 'Archiving'.
[11] For the definition of publication used by the National Library of Australia in regard to PANDORA, see http://pandora.nla.gov.au/selectionguidelines.html#pubdefinition
[12] http://www.apple.com/webobjects/
[13] See footnote 3 for an explanation of PANDORA nomenclature.
[14] The term 'user' is used throughout this paper to refer to collection managers within PANDORA partner agencies who are registered on PANDAS as Standard Users or higher. That is they are the business users of the system who undertake the archiving activities. They may also be referred to as title owners throughout this paper.
[15] The PANDAS user manual providing screenshots of the system and procedural detail is available online at: http://pandora.nla.gov.au/manual/pandas/index.html
[16] http://www.towersoft.com/solutions/t_rec_mgt.htm
[17] WinHTTrack is the Windows version of the HTTrack software. See footnote 6 for URL.
[18] This is yet to be tested.
[20] A desired enhancement to PANDAS aims to make this directory view more readily accessible.
[21] For a discussion of the development of the National Library of Australia's digital services architecture, including the DOSS, see Cathro, Warwick and Boston, Tony. Development of a Digital Services Architecture at the National Library of Australia. (2003) http://www.nla.gov.au/nla/staffpaper/2003/cathro1.html
[22] One limitation of the system, which is designed primarily as a downloading system, is that when resources are uploaded to the Archive the Perl scripts that are normally run with harvesting are not initiated. Thus, for example the shadow archive for preservation metadata is not created.
[23] For more information on the schema and associated resolver service, see: Persistent Identifier Scheme for Digital Collections at the National Library of Australia. http://www.nla.gov.au/initiatives/nlapi.html
[24] http://pandora.nla.gov.au/cgi-bin/cite.pl
[25] The AGLS standard is used. See: http://www.naa.gov.au/recordkeeping/gov_online/agls/summary.html
[26] http://www.proclarity.com/index.asp
[28] http://www.netpreserve.org/about/deepweb.php
[29] Catherine Lupovici, Head of Digital Library Department, Bibliothèque nationale du France, made this point in her unpublished keynote address at the 2004 VALA (Victorian Association for Library Automation) Conference in Melbourne, 3-5 February 2004. Conference web site at: http://www.vala.org.au/conf2004.htm
![]()
| About This Site | Copyright | Privacy | Accessibility | Site Map | Site Search | Content A-Z | Contact Us |